Previously, we created a gRPC reference data service for stocks using Tonic. We intentionally left the implementation for the persistence layer as a TODO for later. In this post, we will zoom in on the repository, implementing the Postgres repository with the help of SQLx.
Everything we do in this section will take place inside the ./api/ directory.
Unless otherwise specified, any command needs to be run within the directory.
Introduction to SQLx
We’ll use SQLx to interface with the database. SQLx is a crate that enables compile-time checked queries, allowing you to write plain SQL queries while ensuring that your Rust types adhere to the schema and queries you’ve defined. It is a unique and refreshing approach to interfacing with a database in a world where ORMs are so pervasive.
SQLx works by connecting to a live database at compile time to verify your types. Unlike in some ORMs, where the schema is generated from the types and you run migrations to keep the database in sync, SQLx requires you to update the database first. It then checks that the Rust code is compatible with the schema.
To facilitate this, SQLx comes with a CLI tool that assists with evolving the database
through migrations. The CLI tool is also required to prepare the database for offline
mode - this is needed in CI/CD pipelines where there is no access to a live database.
Creating the schema
To start the local database, let’s use docker compose.
docker compose up -d dbSQLx requires the database URL to conect. Let’s start by updating
the .env file we previously created and setting the database URL to match what
we specified in the docker-compose.yml file.
DATABASE_URL=postgres://postgres:dummy@localhost:5432/tradingNote that we appended /trading to the URL. This database doesn’t exist yet,
but we can use the CLI to create it:
sqlx database createOur reference data service only needs a very simple stocks table, which
stores the symbols and names of various stocks. Let’s create a new migration
where we can specify the query to create the table.
sqlx migrate add -r stocksThis will create a new migrations directory with two files ending in
down.sql and up.sql. Because we passed in the -r flag, SQLx will
create two-way migrations, where the down.sql script should revert
the migration carried out by the up.sql script.
Add this query to the up file:
CREATE TABLE stocks( id SERIAL PRIMARY KEY, symbol VARCHAR(10) UNIQUE NOT NULL, name VARCHAR(255) NOT NULL);You can run the migration using the CLI:
sqlx migrate runApart from the stocks table, this also creates a new _sqlx_migrations
table which keeps track of the already applied migrations. If you were to
run the migrate run command again, it would do nothing.
Let’s also add the down script quickly:
DROP TABLE stocks;You can revert the last migration by calling the
sqlx migrate revertcommand. This will execute the corresponding down script.
Adding SQLx as a project dependency
All this has worked without adding sqlx as a dependency to the Cargo
project, as we had previously installed the SQLx CLI. Now that we are
ready to work on the Rust code, let’s add the SQLx crate to the project as well.
9 collapsed lines
[package]name = "trading-api"version = "0.1.0"edition = "2021"
[dependencies]anyhow = "1.0.79"dotenvy = "0.15"prost = "0.12"prost-types = "0.12"sqlx = { version = "0.7", features = [ "bigdecimal", "chrono", "migrate", "postgres", "runtime-tokio", "time", "tls-rustls" ] }thiserror = "1.0"8 collapsed lines
tokio = { version = "1.35", features = ["rt-multi-thread", "macros"] }tonic = "0.11"tonic-reflection = "0.11"tracing = "0.1.40"tracing-subscriber = { version = "0.3", features = ["env-filter", "json"] }
[build-dependencies]tonic-build = "0.11"Connecting to the database
Before we can implement any useful logic in the repository, we need to create a
connection pool and pass it to the Postgres repository.
Let’s modify the repository so that it takes a PgPool.
pub struct PostgresRefDataRepository { pool: PgPool,}
impl PostgresRefDataRepository { pub fn new() -> Self { Self {} } pub fn new(pool: PgPool) -> Self { Self { pool } }}In main.rs, add a utility function to create a new pool, and use it
to create the repository with the pool passed in.
The complete main module should look like this:
use anyhow::Result;use sqlx::postgres::PgPoolOptions;use sqlx::PgPool;use tonic::transport::Server;use tracing::info;use tracing_subscriber::layer::SubscriberExt;use tracing_subscriber::util::SubscriberInitExt;
use trading_api::refdata::{PostgresRefDataRepository, RefDataService};use trading_api::services::proto::refdata::ref_data_server::RefDataServer;use trading_api::services::FILE_DESCRIPTOR_SET;
#[tokio::main]async fn main() -> Result<()> { dotenvy::dotenv()?; setup_tracing_registry(); let pool = pg_pool().await?;
let reflection_service = tonic_reflection::server::Builder::configure() .register_encoded_file_descriptor_set(FILE_DESCRIPTOR_SET) .build()?; let refdata_service = RefDataServer::new(build_refdata_service(pool.clone()));
let address = "0.0.0.0:8080".parse()?; info!("Service is listening on {address}");
Server::builder() .add_service(reflection_service) .add_service(refdata_service) .serve(address) .await?;
Ok(())}
fn build_refdata_service(pool: PgPool) -> RefDataService<PostgresRefDataRepository> { let repository = PostgresRefDataRepository::new(pool); RefDataService::new(repository)}
pub async fn pg_pool() -> Result<PgPool> { let url = std::env::var("DATABASE_URL")?; let pool = PgPoolOptions::new() .max_connections(5) .connect(url.as_str()) .await?;
Ok(pool)}
fn setup_tracing_registry() { tracing_subscriber::registry() .with(tracing_subscriber::EnvFilter::new( std::env::var("RUST_LOG").unwrap_or_else(|_| "info,trading_api=debug".into()), )) .with(tracing_subscriber::fmt::layer().pretty()) .init();}Implementing the repository
The repository now has access to the database through the connection pool. It’s time to get our hands dirty with SQLx!
Adding a new stock
Let’s revisit the stub function we created in the Postgres repository for adding a new stock. We can now replace the TODO with a few lines of SQLx code to insert a new stock into the database.
We will use the query_as! macro, which allows us to specify the expected
return type of the query.
As its second argument, it takes
the query string. The following arguments are bound to the arguments in the query.
27 collapsed lines
use sqlx::PgPool;
use crate::error::Result;use crate::refdata::models::Stock;
#[tonic::async_trait]pub trait RefDataRepository { async fn get_all_stocks(&self) -> Result<Vec<Stock>>; async fn add_stock(&self, symbol: &str, name: &str) -> Result<Stock>;}
pub struct PostgresRefDataRepository { pool: PgPool,}
impl PostgresRefDataRepository { pub fn new(pool: PgPool) -> Self { Self { pool } }}
#[tonic::async_trait]impl RefDataRepository for PostgresRefDataRepository { async fn get_all_stocks(&self) -> Result<Vec<Stock>> { todo!() }
async fn add_stock(&self, symbol: &str, name: &str) -> Result<Stock> { let stock = sqlx::query_as!( Stock, "INSERT INTO stocks (symbol, name) VALUES ($1, $2) RETURNING id, symbol, name", symbol, name ) .fetch_one(&self.pool) .await?;
Ok(stock) }1 collapsed line
}If you were to try to compile this, it would fail with an error complaining about the compiler struggling to convert the error to our Result type. Let’s tackle this issue next.
Handling SQLx errors
The thiserror error type we previously created in src/error.rs needs to be extended
with a new variant so that SQLx errors are correctly handled. We will also improve the
mapping logic so that RowNotFound errors are mapped to the NotFound gRPC status,
and SQL check violations are mapped to InvalidArgument. This is not a perfect mapping,
but it works for demonstration purposes.
use tonic::{Code, Status};use tracing::error;
#[derive(Debug, thiserror::Error)]pub enum Error { #[error("sql error")] Sqlx(#[from] sqlx::Error), #[error("other error")] Other(#[from] anyhow::Error),}
pub type Result<T> = std::result::Result<T, Error>;
impl From<Error> for Status { fn from(err: Error) -> Self { match err { Error::Sqlx(sqlx::Error::RowNotFound) => { Self::new(Code::NotFound, "not found".to_string()) } Error::Sqlx(sqlx::Error::Database(err)) => { let code = if err.is_check_violation() { Code::InvalidArgument } else { Code::Internal }; Self::new(code, err.to_string()) } _ => { let error_message = err.to_string(); error!(error_message, "internal error: {:?}", err); Self::new(Code::Internal, error_message) } } }}After making these changes, everything should compile again.
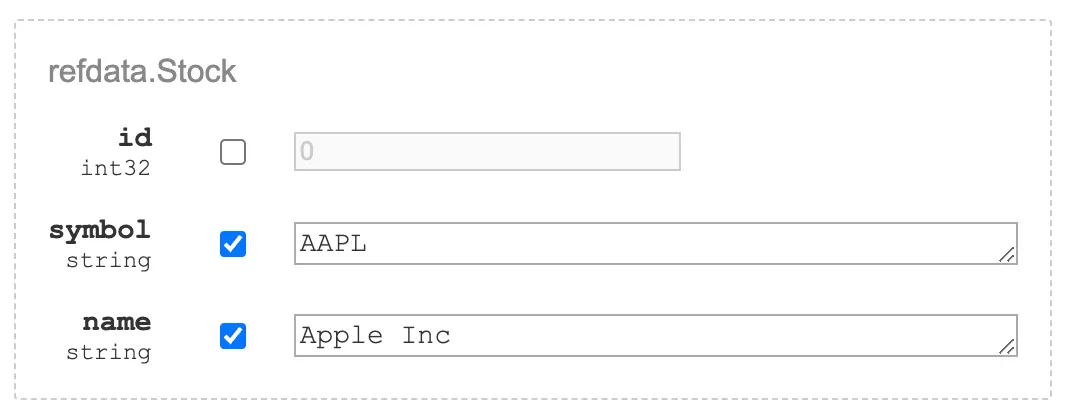
Use grpcui to test the AddStock method. The id field of the stock
should be left unspecified as this is only used for responses.
Retrieving all stocks
Finally, let’s implement the function to retrieve all stocks.
22 collapsed lines
use sqlx::PgPool;
use crate::error::Result;use crate::refdata::models::Stock;
#[tonic::async_trait]pub trait RefDataRepository { async fn get_all_stocks(&self) -> Result<Vec<Stock>>; async fn add_stock(&self, symbol: &str, name: &str) -> Result<Stock>;}
pub struct PostgresRefDataRepository { pool: PgPool,}
impl PostgresRefDataRepository { pub fn new(pool: PgPool) -> Self { Self { pool } }}
#[tonic::async_trait]impl RefDataRepository for PostgresRefDataRepository { async fn get_all_stocks(&self) -> Result<Vec<Stock>> { let stocks = sqlx::query_as!(Stock, "SELECT id, symbol, name FROM stocks",) .fetch_all(&self.pool) .await?;
Ok(stocks) }14 collapsed lines
async fn add_stock(&self, symbol: &str, name: &str) -> Result<Stock> { let stock = sqlx::query_as!( Stock, "INSERT INTO stocks (symbol, name) VALUES ($1, $2) RETURNING id, symbol, name", symbol, name ) .fetch_one(&self.pool) .await?;
Ok(stock) }}You should be able to retrieve any stock you’ve added using grpcui.
Testing
An important area we haven’t covered is testing. SQLx has built-in testing utilities to create isolated test databases, apply migrations and fixtures, and tear down the database at the end.
My preferred way of testing gRPC services is integration tests that call the endpoint functions directly (but without actually running the service).
Let’s start by creating the tests directory and a subdirectory tests/fixtures.
Fixtures are written as SQL files and can contain arbitrary SQL code.
Create a file called stocks.sql and add a few stocks to be used in tests.
INSERT INTO stocks (symbol, name)VALUES ('AAPL', 'Apple Inc.'), ('GOOG', 'Alphabet Inc.'), ('MSFT', 'Microsoft Corporation'), ('AMZN', 'Amazon.com, Inc.'), ('JPM', 'JPMorgan Chase & Co.');We’ll use these stocks as baseline reference data in several tests.
To mark tests as SQLx tests, we can use the sqlx::test macro.
You can pass in the fixtures you’d like to apply for the particular
test, for example
#[sqlx::test(fixtures("stocks"))]async fn test_all_stocks(pool: PgPool) { todo!()}The test needs to take PgPool as its argument for the SQLx functionality
to kick in.
Create a new test module refdata.rs inside the tests directory and
add a simple test for retrieving all stocks and adding a new stock.
use sqlx::PgPool;use tonic::Request;
use trading_api::refdata::{PostgresRefDataRepository, RefDataService};use trading_api::services::proto::refdata::ref_data_server::RefData;use trading_api::services::proto::refdata::Stock;
#[sqlx::test(fixtures("stocks"))]async fn test_all_stocks(pool: PgPool) { let service = create_service(pool);
let request = Request::new(()); let response = service.all_stocks(request).await.unwrap();
assert_eq!(response.get_ref().stocks.len(), 5);}
#[sqlx::test]async fn test_add_stock(pool: PgPool) { let service = create_service(pool);
let request = Request::new(()); let response = service.all_stocks(request).await.unwrap(); assert_eq!(response.get_ref().stocks.len(), 0);
let stock = Stock { id: -1, // this will be set by the database symbol: "JPM".to_string(), name: "JPMorgan Chase & Co.".to_string(), }; service.add_stock(Request::new(stock)).await.unwrap();
let request = Request::new(()); let response = service.all_stocks(request).await.unwrap(); assert_eq!(response.get_ref().stocks.len(), 1);
let stock = response.get_ref().stocks.first().unwrap(); assert_eq!(stock.symbol, "JPM"); assert_eq!(stock.name, "JPMorgan Chase & Co.");}
fn create_service(pool: PgPool) -> RefDataService<PostgresRefDataRepository> { let repository = PostgresRefDataRepository::new(pool); RefDataService::new(repository)}This isn’t a comprehensive test suite of course, but the same concepts can be applied to cover edge cases and more complex scenarios.
Revised GitHub actions
The GitHub Actions included in the repository no longer pass due to new dependencies on Protobuf, SQLx, and the database.
SQLx can work in CI/CD pipelines in two modes - either running against a database (like we’ve been using it locally) or in offline mode. We’ll demonstrate the use of both modes in our pipeline.
Offline mode
For the build step and Clippy checks, let’s use offline mode, as these steps
don’t actually require a running database. The SQLX_OFFLINE=true flag can be used
to ensure SQLx uses offline mode. We can use the SQLx CLI to generate meta files for our queries,
which SQLx uses at compile time in offline mode to verify the queries against.
cargo sqlx prepareYou should see a new .sqlx directory appear with JSON files in it. Make sure you commit
these files into git.
Finally, add the SQLX_OFFLINE flag to the individual steps.
11 collapsed lines
name: CI
on: push: branches: ['main'] pull_request: branches: ['main']
env: CARGO_TERM_COLOR: always
jobs: api-checks: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Install Protoc uses: arduino/setup-protoc@v3 - name: Build working-directory: ./api env: SQLX_OFFLINE: true run: cargo build --verbose - name: Run Clippy working-directory: ./api env: SQLX_OFFLINE: true run: cargo clippy --all-targets --all-features -- -Dclippy::all -D warnings - name: Run tests working-directory: ./api run: cargo test --verbose
19 collapsed lines
webapp-checks: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-node@v4 with: node-version: 20 - name: Install packages working-directory: ./webapp run: npm ci - name: Typecheck working-directory: ./webapp run: npm run typecheck - name: Lint working-directory: ./webapp run: npm run lint - name: Format working-directory: ./webapp run: npm run formatcheckNote, we also added a step to install protoc so the pipeline can compile
proto files.
Tests against a running database
For running integration tests in the pipeline, we will need an actual database.
Let’s add a Postgres service, set the DATABASE_URL for SQLx and run the
SQLx CLI to prepare the database.
8 collapsed lines
name: CI
on: push: branches: ['main'] pull_request: branches: ['main']
env: CARGO_TERM_COLOR: always DATABASE_URL: postgres://postgres:dummy@localhost:5432/trading
jobs: api-checks: runs-on: ubuntu-latest services: postgres: image: postgres:16 env: POSTGRES_USER: postgres POSTGRES_PASSWORD: dummy options: >- --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5 ports: - 5432:5432 steps: - uses: actions/checkout@v3 - name: Install Protoc uses: arduino/setup-protoc@v3 - name: Build working-directory: ./api env: SQLX_OFFLINE: true run: cargo build --verbose - name: Run Clippy working-directory: ./api env: SQLX_OFFLINE: true run: cargo clippy --all-targets --all-features -- -Dclippy::all -D warnings - name: Setup database working-directory: ./api run: | cargo install sqlx-cli --no-default-features --features postgres sqlx database create sqlx migrate run - name: Run tests working-directory: ./api run: cargo test --verbose
19 collapsed lines
webapp-checks: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-node@v4 with: node-version: 20 - name: Install packages working-directory: ./webapp run: npm ci - name: Typecheck working-directory: ./webapp run: npm run typecheck - name: Lint working-directory: ./webapp run: npm run lint - name: Format working-directory: ./webapp run: npm run formatcheckWith these changes, our pipeline should be passing again.
Conclusion
By the end of this part in the series, you should have a working refdata service that can add and retrieve stocks from the local Postgres database. All clippy warnings should be gone as we now utilise all the parts we previously developed.
The resulting code can be found in the v2-refdata-persistence branch on GitHub.
In the next part, we’ll follow the same patterns to write the trade service to take orders and calculate overall positions.
Next post - Part 4: The trade service

David Steiner
I'm a software engineer and architect focusing on performant cloud-native distributed systems.